理解Consensus算法 Raft
words: 1.4k views: time: 5minRaft与Paxos算法一样,都是为解决分布式共识问题提出的一种算法。相比Paxos更侧重于理论上的简洁与优美,Raft则更注重工程上的易于理解与实现。可以将Raft与ZAB协议比较,思路和步骤非常相似,但实现过程相对更巧妙一点
Raft算法将一致性算法拆解成了三个相对独立的子问题,如果三个问题都能得到保证,也就能达到算法想要的目标
- Leader Election:选举出一个单一Leader负责log的所有操作,Strong Leader极大的简化了算法的设计
- Log Replication:Leader从Client获取Log,并在其他的Server之间Replicate
- Safety:保证Log和Committed State的一致性
Raft规则

raft.pdf中的这张图已经描述了Raft的所有内容,下面整理下对算法规则的理解
节点三种状态
- 跟随者 Follower
- 候选者 Candidate
- 领导者 Leader
所有节点的状态都是从Follower开始,如果超过Election Timeout(150ms至300ms之间随机)没有收到来自Leader的AppendEntires RPC,那么转变为Candidate,并将term加1;
转为Candidate后会向所有其它节点请求投票,如果从多数节点获得选票,那么转变为Leader;
转为Leader后需要向所有其它节点周期性(heartbeat timeout)发送心跳消息,以阻止其它节点转为Candidate;如果Leader如果从任何RPC的请求或响应中发现有term大于自己的currentTerm,那么将自己转变为Foller,并将currentTerm置为term;
RequestVote RPC 投票请求
1 | type RequestVoteArgs struct { |
如果投票响应中的term大于请求中的term,那么一定返回false,发起RequestVote RPC的候选者会退回Follower,将自己的任期设为响应中的term,重置Election Timeout,并清空选票(每个节点在每次term中只能投一票,之前任期已经作废,现在新的任期可以给其它节点投票),然后等待来自其它节点的投票请求,如果超时没有收到来自新任期Leaderd的消息,那么进入下轮选举,自己再次尝试(尝试前会先term加1);
由于每次重置Election Timeout是随机的,结合任期term的单调递增属性,可以确保在经历有限轮选举后,总能选出一个Leader,避免选举进入死循环;(成为Candidate后会立即发起投票,先给自己投一票;成为Leader后会立即发起心跳阻止其它节点进入选举)
当然只是通过Term机制确保能选出一个Leader还不够,还要是我们期望的那一个,也就是成为Leader的节点要拥有最新的日志。这个就通过参数lastLogTerm和lastLogIndex来进行验证,接收者如果发现候选者的日志比自己还落后的话,那么也会返回false;
AppendEntries RPC 日志复制/心跳消息
1 | type AppendEntriesArgs struct { |
通过entries是否为空来区分请求是日志复制还是心跳消息,term是用来判定当前Leader是否已经过期,如果没有过期再继续下面看是否要追加日志;
每个日志都有两个属性(任期、索引),如果需要追加entries日志条目,需要先判断prevLogIndex和prevLogTerm是否匹配
- 如果Follower在索引prevLogIndex处存在日志,并且term匹配,那么直接追加entries日志条目,返回true(Follower会删除从prevLogIndex + 1开始的所有冲突日志,如果存在的话);
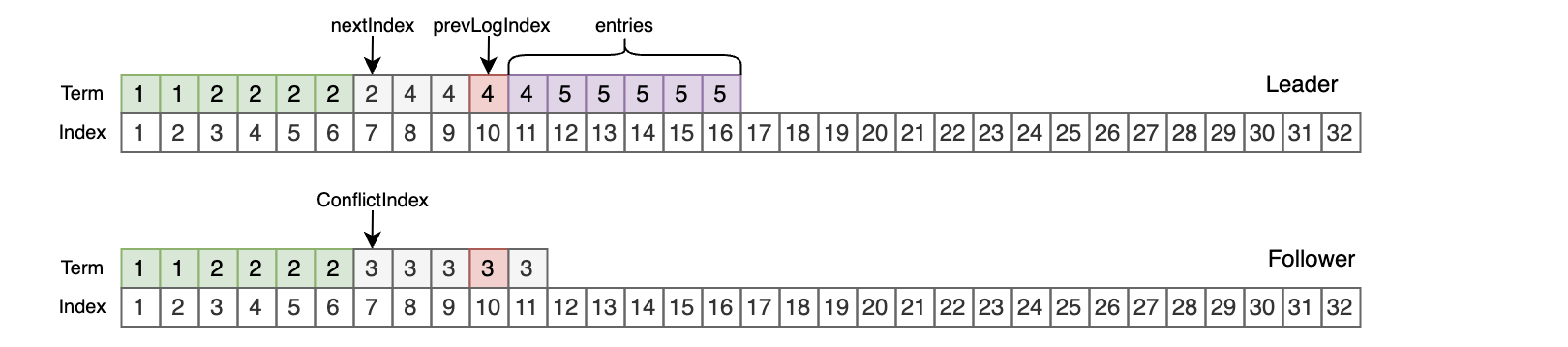
- 如果Follower在索引prevLogIndex处不存在日志,那么返回false,ConflictTerm = -1,ConflictIndex = lastLogIndex + 1;
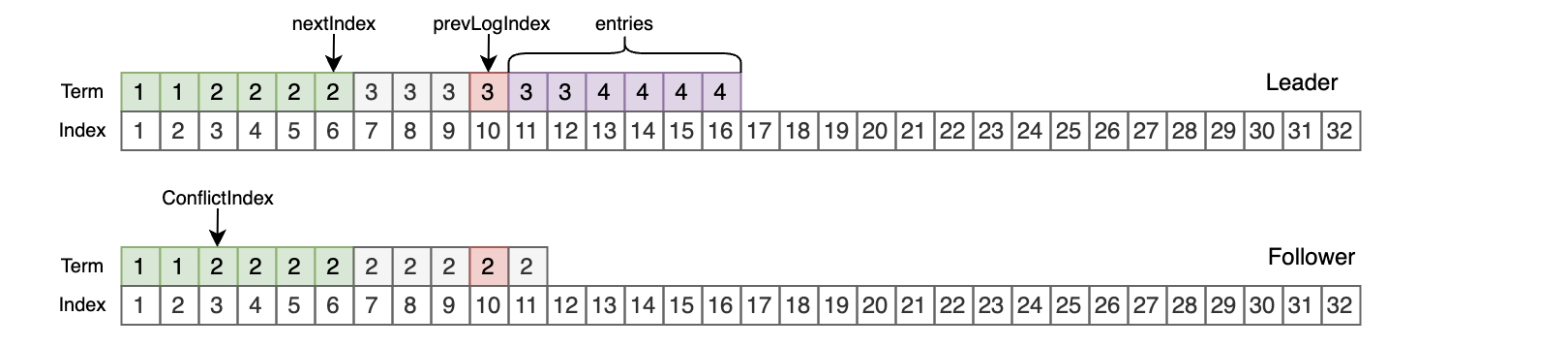
- 如果Follower在索引prevLogIndex处存在日志,但是term不匹配,那么返回false,ConflictTerm = term,ConflictIndex = term任期下的第一条日志索引;
Leader对于场景3中响应的处理(此时ConflictTerm必然小于等于Leader):
- Leader如果自己存在ConflictTerm,那么nextIndex = ConflictTerm任期的最后一条日志索引 + 1,然后从nextIndex以及往后的内容放到entries中;也就是ConflictTerm任期的内容将以Leader为准,Follower中超过Leader的部分将被覆盖更新;
- Leader如果自己不存在ConflictTerm(说明Follower的这段日志是过期的),那么nextIndex = ConflictIndex,然后从nextIndex以及往后的内容放到entries中;当Follower再次收到消息时会重新尝试,如果nextIndex之前能匹配,那么将从nextIndex往后进行覆盖追加;
ZAB协议对比
与ZAB协议类似,Raft的运作过程也是分为两个阶段,领导者选举和日志复制,因此也属于CP系统,选举阶段无法响应外部请求。其中RequestVote RPC确保能够选举出一个正确的Leader,AppendEntries RPC则确保能够准确的复制日志,最终日志提交后应用到状态机进行操作。
参考: