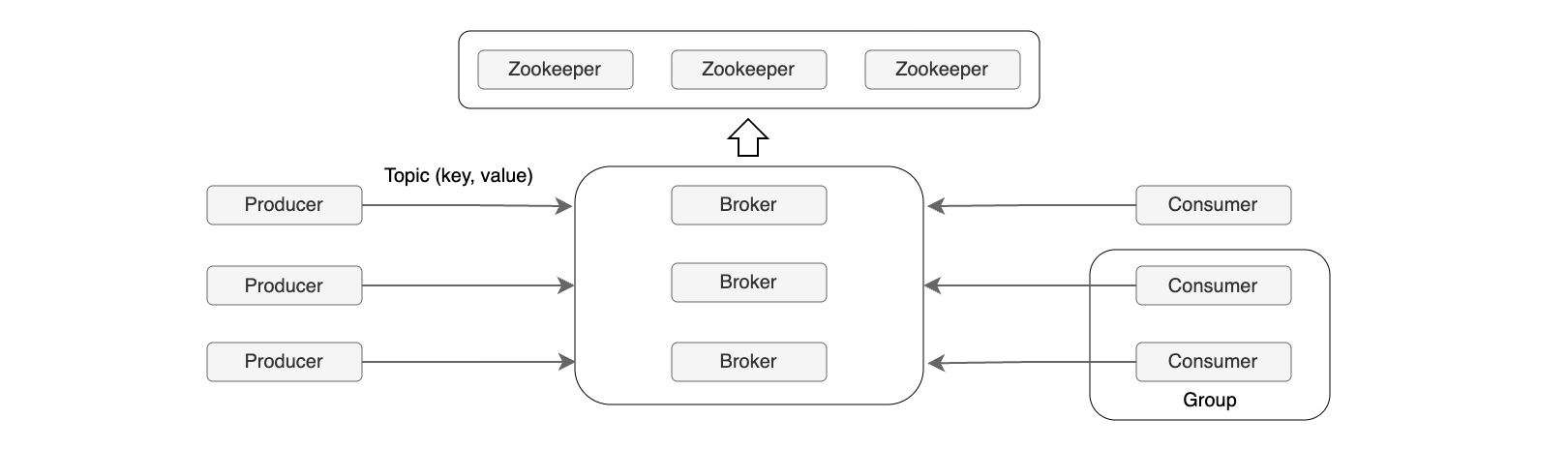
Kafka基本概念
words: 1.3k views: time: 4minKafka是一个高吞吐、低延迟、可水平扩展的分布式流数据平台。核心是一个基于发布/订阅模式的分布式消息系统,以持久化日志的形式存储数据流,兼具消息队列、数据集成和流处理能力。其通过“主题-分区”模型实现数据的并行处理和无限扩展,并借助多副本机制保障高可用与数据可靠性。生产者和消费者可异步解耦,实现每秒百万级的消息处理,是构建实时数据管道和流式应用的核心基础设施。
Kafka的消息组织方式:主题(Topic) -> 分区(Partition) -> 消息,主题下的每条消息只会保存在其中一个确定的分区中。
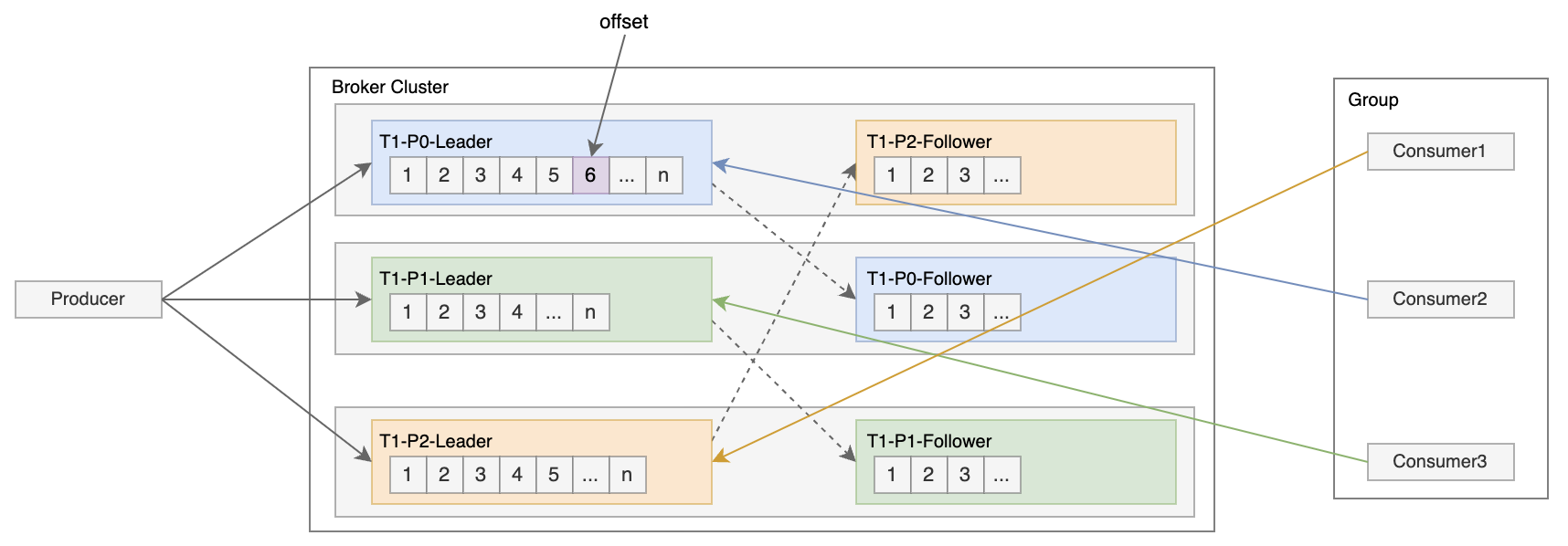
分区
分区是物理上的划分,其主要作用是提供了水平扩展能力,不同的分区能够被放置到不同节点的机器上,而数据的读写也是以分区为单位进行划分的,这样每个节点的机器都能独立地执行各自分区的读写请求处理,那么当性能不足时就可以通过添加新的机器节点来增加整体系统的吞吐量。
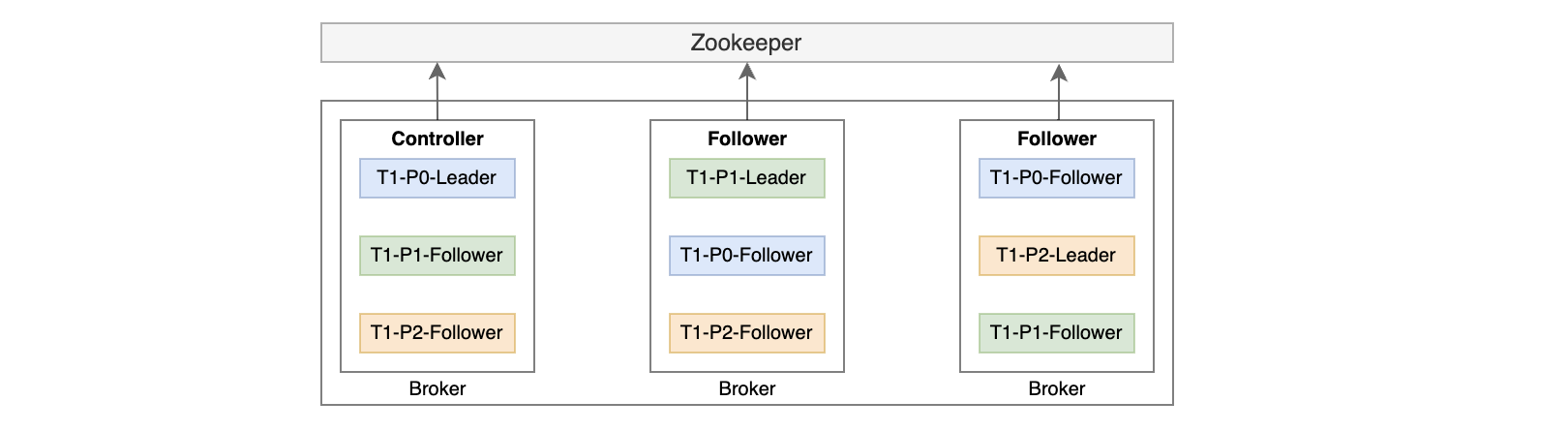
一个分区可以设置多个副本(Replica),分为一个主副本和多个从副本,分布在不同的机器节点上,当主副本所在节点发生故障时,Kafka可以从同步的从副本中选举出一个新的主副本继续对外提供服务,以此实现故障转移,所以设置副本可以提升系统的高可用性。
假设有三个节点,一个Topic的分区数和副本数都设置为3:
分区策略,先看是否有指定分区,如果未指定,再看是否指定了key,根据key的hash选择分区;如果也没有指定key,那么使用轮询的方式选择分区;
主题
主题是逻上的划分,假设Topic的分区数设为3,副本数设为2
生产者发送的消息会封装成一个ProducerRecord对象。对象的参数包括:
1 | topic string NotNull |
ACK应答机制,据可靠性和延迟要求的权衡,Kafka提供了三种可靠性级别
1 | 0 不等待Broker的ACK,延迟最低,Broker收到数据立即返回(还没有写入磁盘),如果Broker故障可能丢失数据 |
副本同步策略,如果设置所有Follower完成同步才返回ACK,那么有一个Follower出现故障,就会导致Leader一直等待
1 | 分区Leader会维护一个动态的ISR(in-sync replica set),包括Leader,和所有保持同步的Follower集; |
Consumer Group的分区分配策略,默认partition.assignment.strategy是CooperativeSticky
1 | RoundRobin 将所有主题的分区混合排序,按消费者字典序轮询分配,分配更均衡 |
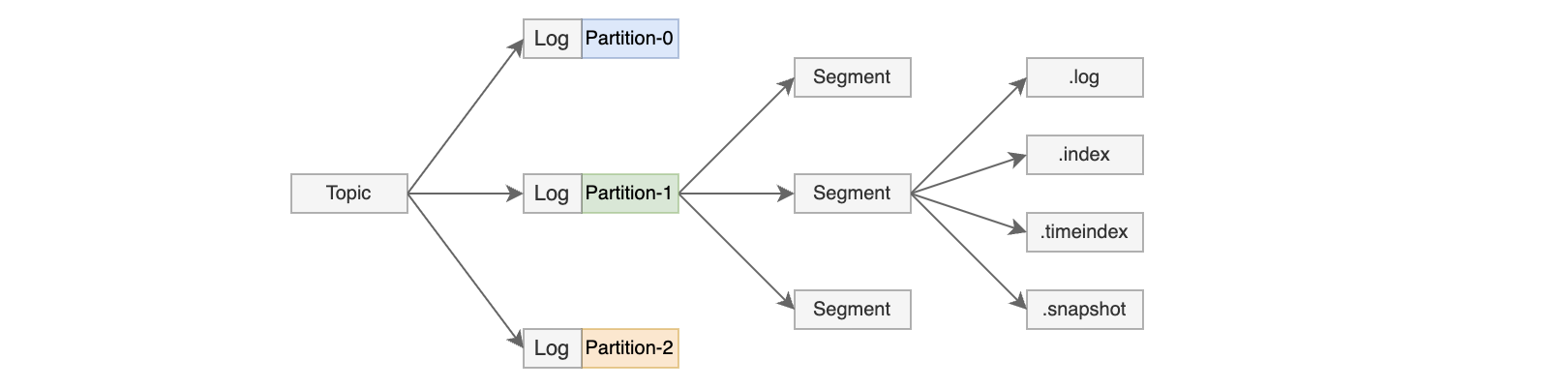
数据日志
以Partition为单位划分文件夹,名称格式:Topic名称-分区号,其中的文件再分为多段Segment,每段Segment有4个文件,以第一条消息的offset进行命名
1 | .log文件 数据文件,存储实际的消息内容(键、值、时间戳等)和元数据,是日志的主体 |
参考: