Mysql基本原理
words: 2.7k views: time: 9min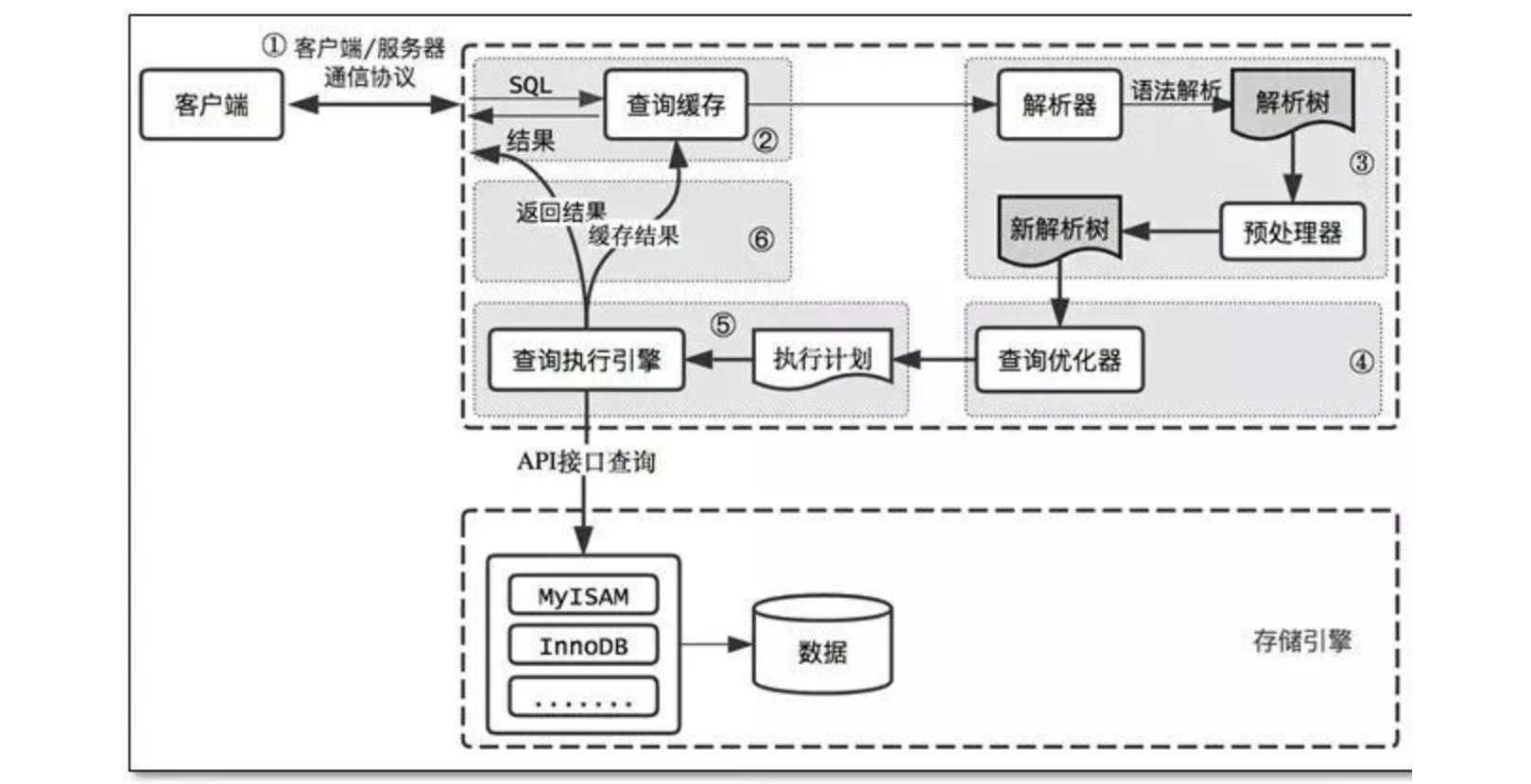
数据库可以理解成就是一个管理数据文件的基础软件,它介于应用和数据之间。Mysql使用ibd文件来存放表数据,它将数据拆成一个个数据页,每页默认16KB,这样在读写部分表数据时,只需读取磁盘中对应的几个数据页,而不用读写整个ibd文件。
数据页
为了更好的查询数据页,会为每个数据页添加页号,再为每行数据加个序号(主键),然后按主键大小排序,将每个数据页里最小的主键序号和所在页的页号提出来,使用B+树进行层级组织(InnoDB主键采用聚簇索引,叶子节点直接存在行数据,使用其它索引查询数据时,需要先转化成主键再获取数据,称为回表)
根据聚簇索引的特点,如果单行数据体积越大,叶子节点所能存储的数据行就越少,然后就需要分裂更多的数据页,从而导致B+树的层级越高,查询需要更多的IO,最终影响查询性能。所以一般在设计表结构时,可以考虑将大体积字段和不常用的字段进行分表设计。
Buffer Pool
磁盘IO是数据库性能的瓶颈,所以Buffer Pool的目的就是通过内存缓存减少磁盘IO,提升读写性能。读取数据时,直接从内存读取,如果没有再去磁盘读取,以数据页为单位载入内存。修改数据时,也是先操作Buffer Pool中的缓存页,修改后标记为脏页,然后由后台线程择机进行批量刷盘。
所以缓存命中率是Buffer Pool的核心指标,命中率越高,磁盘IO越少,性能越好。
- 预读失效问题
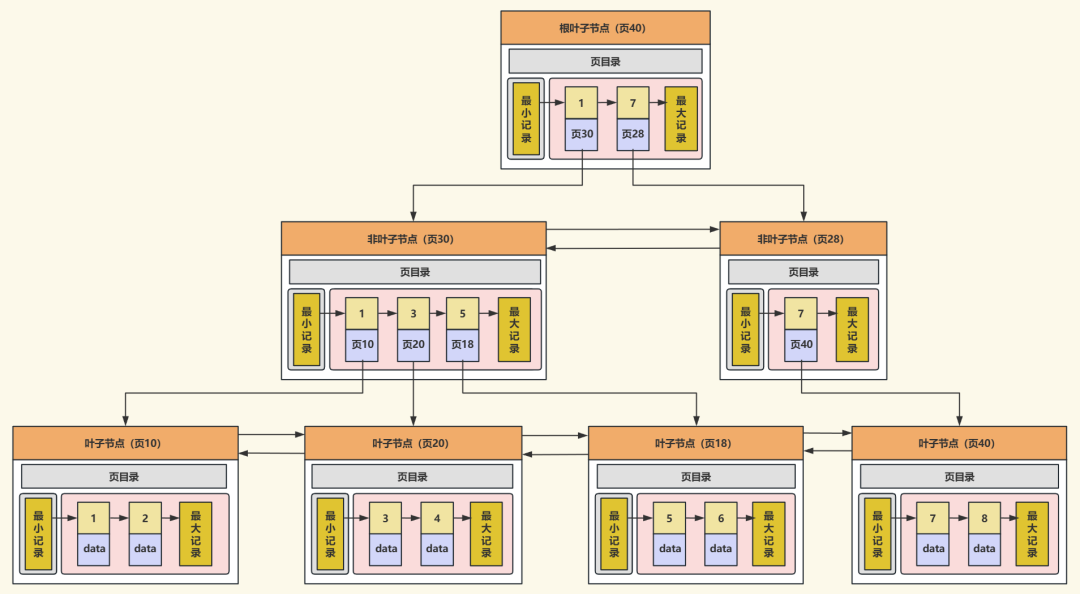
InnoDB会利用空间局部性,加载数据页时提前加载相邻页(预读),减少磁盘IO,但如果预读的页没被访问,就是预读失效。所以思路是在LRU基础上进行优化,分成young区和old区(后37%,innodb_old_blocks_pct参数,默认37)。
加载时预读页先放入old区头部,只有预读页被真正访问时才转移到young区头部,然后未被访问的预读页会从old区尾部淘汰,不影响young区热点数据。
另外,young区前1/4的页被访问时,不会移动到头部,避免频繁移动带来的开销。
- Buffer Pool污染问题
当执行全表扫描(比如索引失效)时,即使结果集很小,也会把大量磁盘页加载到Buffer Pool,淘汰掉原本的热点数据,导致后续访问频繁命中磁盘——这就是Buffer Pool污染,解决办法是增加时间判断(由innodb_old_blocks_time参数控制,默认1000ms):
old区的页第一次被访问时,会记录访问时间,只有后续访问时间与第一次访问时间间隔超过1秒,才把页转移到young区头部。这样全表扫描时加载的页,短期内频繁访问但间隔小于1秒,不会进入young区,避免淘汰热点数据。
- 脏页的刷盘时机
脏页刷盘不能太频繁(影响性能),也不能太滞后(怕数据丢失),InnoDB会在以下4个时机批量刷盘:
- redo log日志满了(必须刷盘,否则无法继续写日志,刷盘的不是redo log,而是脏页,为了腾出空间);
- Buffer Pool空间不足(淘汰页时,若淘汰的是脏页,需先刷盘);
- MySQL空闲时(后台线程定期刷盘,不影响业务);
- MySQL正常关闭时(确保所有脏页都刷盘,避免数据丢失);
如果慢SQL监控中偶尔出现耗时稍长的SQL,可能是脏页刷盘带来的性能开销。若频繁出现,可以考虑调大Buffer Pool或redo log大小。
日志
undo Log & MVCC
undo log回滚日志,是InnoDB存储引擎特有的日志,它保证了事务ACID特性中的原子性(Atomicity),记录的是逆向逻辑操作,用于记录数据被修改前的信息。它的主要作用有两个:事务回滚和通过ReadView + undo log实现MVCC(多版本并发控制)
- 事务回滚

一条记录的每次更新都会产生undo log,它有一个roll_pointer指针和一个trx_id事务。通过trx_id可以知道该记录是被哪个事务修改的,通过roll_pointer指针可以将这些undo log串成一个链表,这个链表就被称为版本链。
事务发生回滚时,会读取undo log里的数据,本质上并不会以执行反SQL的模式还原数据,而是直接将roll_ptr回滚指针指向Undo记录。
- MVCC
在MVCC出现之前,数据库主要依靠锁机制来解决并发冲突,但锁是以牺牲性能为代价的。而MVCC的思路是为每一行数据维护多个版本,通过某个时间点的快照(Snapshot)来读取数据,从而避免加锁带来的性能损耗,以非阻塞的方式实现事务所需的隔离级别。
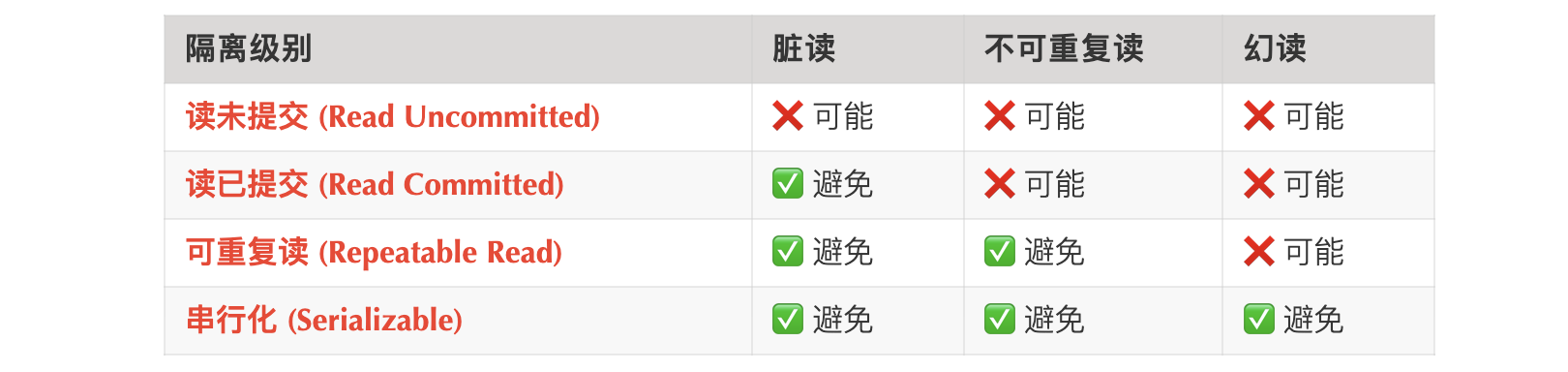
READ UNCOMMITTED:事务可以查看其他事务中还没有提交的修改,这个级别不用加任何锁,但也容易导致很多问题,比如脏读(dirty read),所以在实际应用中很少使用。
READ COMMITTED:大多数数据库的默认隔离级别,一个事务可以看到其他事务在它开始之后提交的修改。思路是每次读都取已提交的最新快照,也就是基于MVCC,每次SELECT查询都会生成一个独立的、最新的ReadView。
REPEATABLE READ:Mysql默认隔离级别,同一个事务中多次读取相同行数据的结果永远是一样的。也是基于MVCC,但一个事务中只有第一次SELECT查询时会生成ReadView,后续所有读操作都复用这个 ReadView。
另外,InnoDB在RR级别上也解决了幻读问题,通过Next-Key Lock(临键锁)实现。它结合了记录锁(锁住索引项)和间隙锁(锁住索引项之间的间隙)。当执行范围查询时,InnoDB 会锁住整个范围,防止其他事务在这个范围内插入新数据,从而避免了幻读。
SERIALIZABLE:退化为基于锁的并发控制,完全摒弃MVCC。读取的每一行数据上都会加锁,所以可能导致大量的超时和锁争用的问题,实际应用中也很少用。
- Read View
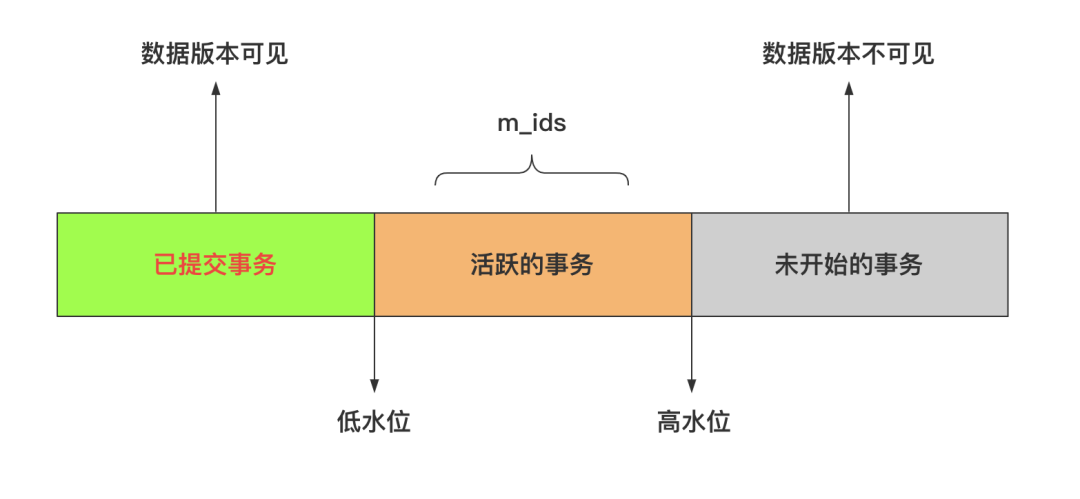
ReadView是InnoDB用来实现MVCC的核心数据结构,它记录了当前系统中所有活跃事务(已开启但未提交)的ID列表,从而决定当前事务能看到哪些版本的数据。
class ReadView { |
但是它只用于已提交读和可重复读两个隔离级别,这两个隔离级别的不同点就在于什么时候生成Read View。
redo log
redo log重做日志,也是InnoDB存储引擎特有的日志,记录内容是数据页的物理修改,它是事务持久性的实现基础,用于掉电等故障的数据恢复;
其思路是WAL(Write-Ahead Logging)写前日志技术,事务在commit时,先将redo log刷盘,而不用等待对应的脏页刷入磁盘。由于内存的脏页数据是随机分散在磁盘上的,而redo log file可以顺序写,其性能是随机写的几十倍,所以能大大加快事务提交流程。
- checkpoint
redo log默认情况下存储在data目录下 ib_logfile0 和 ib-logfile1 两个文件中(可以通过innodb_log_file_size设置大小,innodb_log_files_in_group设置文件个数),Mysql会通过来回写这两个文件的形式记录日志,形成一个环
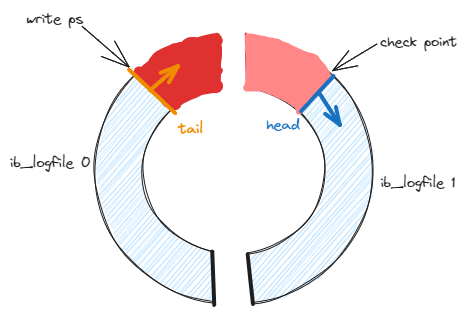
check point:表示目前哪些redo log记录已经失效,且可以被擦除(覆盖) |
bin log
bin log是Mysql在服务层记录的操作日志,主要用于实现主从复制(集群同步)和数据备份恢复(PITR时间点恢复)。
bin log是通过追加的方式进行写入的,可以通过max_binlog_size参数设置每个binlog文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。文件的命名为mysql-bin.000001、mysql-bin.000002、mysql-bin.00000x….,可以通过show binary logs;命令查看已有的bin-log日志文件。
- 主从复制
Mysql的主从复制是异步串行化的,也就是说主库上执行事务操作的线程,不会等待复制binlog的线程同步完成,示意如下:
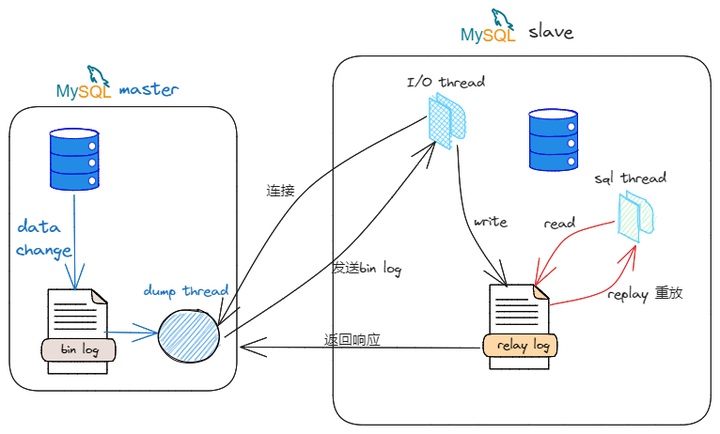
写入:主库写bin log 日志,提交事务,并更新本地存储数据; |
- 2PC两阶段提交日志
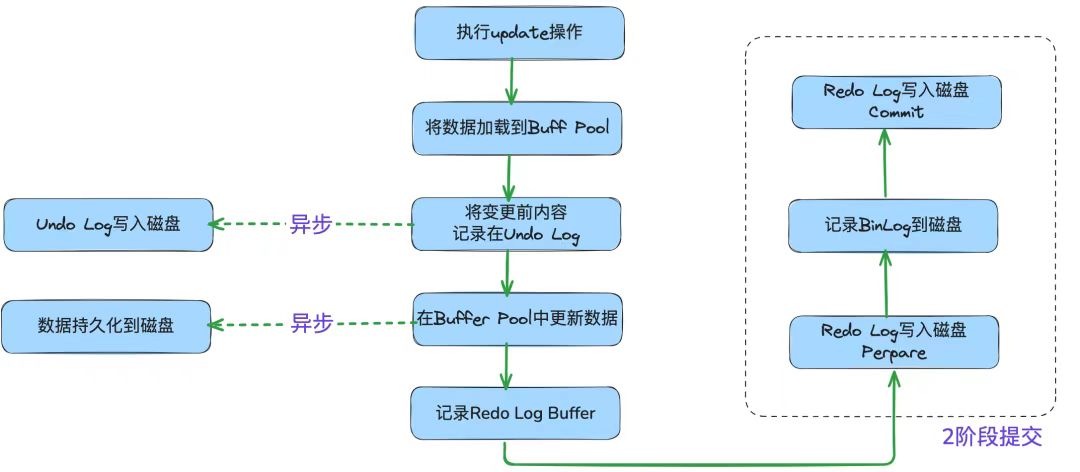
由于redo Log在引擎层,bin log在Server层,所以就有个问题,怎么保证两个日志的内容一致?
准备阶段:redo log prepare,将事务的redo log刷盘,状态标记为prepare; |
如果bin log写入失败:此时redo log状态为prepare,Mysql恢复时会检查bin log,发现没有对应的事务XID(事务唯一标识),就知道Server层还没确认完成。为了保证主从一致(从库没收到bin log),会用undo log回滚事务;
如果redo log提交失败:此时bin log已完成写入,Mysql恢复时检查到bin log有对应的XID,就知道Server层已完成确认完成。就是redo log不是Commit状态,也会直接提交事务(因为bin log可能已经同步到从库,主库必须认账,否则主从数据会不一致)
总结
可以用一次修改提交的过程来说明,示意如下:
参考: