Linux I/O模型
words: 3.7k views: time: 13min操作系统负责对计算机资源进行管理,并对上层应用提供支持。其核心是操作系统内核空间,独立于应用程序,可以访问受保护的内存空间以及底层硬件设备。为了保证内核的安全,避免用户进程直接操作内核,因此将内存空间划分为两部分,即内核空间和用户空间。
一个进程通过调用内核打开相应的文件,告诉内核它想访问某个 I/O 设备,内核返回一个非负整数,称为描述符。后续对此文件的所有操作通过这个描述符进行,内核会记录有关这个打开文件的所有信息,而应用进程只需记住这个描述符。其中,Linux内核用三个相关的数据结构来表示打开的文件:
描述符表: 每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的,每个打开的描述符表项指向文件表中的一个表项
文件表:打开文件的集合由一张文件表来表示,所有的进程共享这张表。每个文件表的表项组成包括当前文件的位置、引用计数(指向当前表项的描述符数目)、以及一个指向 v-node 表中对应表项的指针。关闭一个描述符会减少相应的文件表表项中的引用计数,内核不会删除这个文件表表项,直到它的引用计数为零
v-node表: 与文件表一样,所有进程共享 v-node 表。每个表项包含 stat 结构中的大多数信息,包括 st_mode 和 st_size 成员
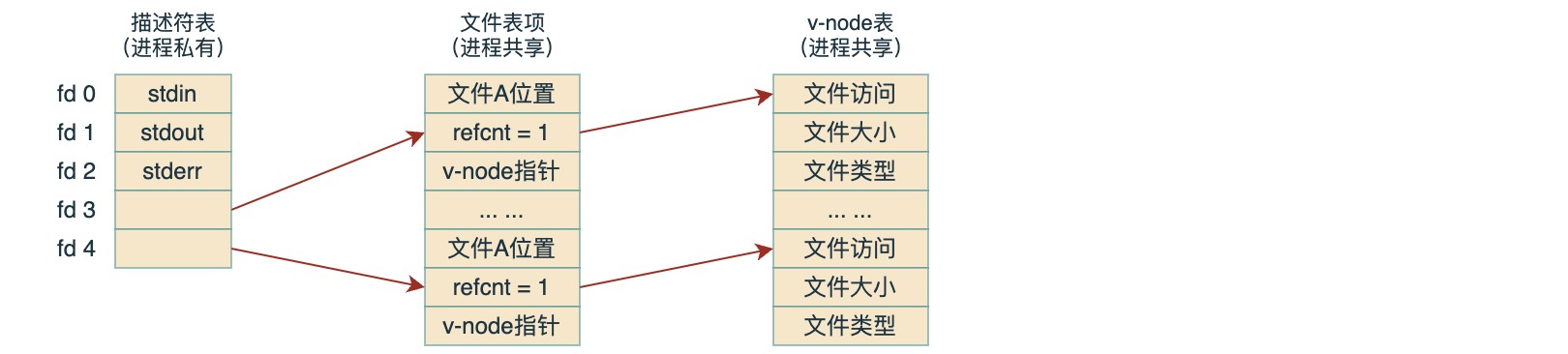
多个描述符也可以通过不同的文件表项来引用同一个文件,例如以同一个 filename 调用 open 函数两次,就会发生这种情况。另外,Linux shell创建的每个进程开始时都有三个打开的文件:标准输入(STDIN_FILENO=0)、标准输出(STDOUT_FILENO=1)和标准错误(STDERR_FILENO=2)
1. 磁盘IO
1.1. 缓存IO
大多数文件系统的默认 I/O 操作都是缓存 I/O,所以一般也称为标准 I/O 操作。以读操作为例,应用程序需要走 read 系统调用,这样数据会先拷贝到操作系统的内核缓存,然后再从内核拷贝到应用进程空间。反之写操作,需要走 write 调用,也是类似的。

根据程序的局部性原理,最近被访问的信息很可能还要被访问(时间局部性),以及与最近被访问数据邻近的数据也可能被访问(空间局部性)。因此实际读取时,操作系统会帮进程作一部分预读,这样的好处是可以减少对 I/O 设备的实际访问次数,但由于读写操作都要先经过内核缓存,然后再复制到用户空间,因此也多了一次内存复制操作。
1.2. 页缓存 PageCache
PageCache 是操作系统对文件的缓存,用来减少对磁盘的 I/O 操作,以页为单位的,内容就是磁盘上的物理块,页缓存能让程序对文件进行顺序读写时的速度几乎接近于内存的读写速度,主要原因就是由于 OS 使用 PageCache 机制对读写访问操作进行了一下缓冲。
页缓存读取策略:当进程发起一个 read 调用时,系统首先会检查需要的数据是否在页缓存中,如果在,则直接从页缓存中读取,否则内核调度块 I/O 操作从磁盘去读取数据,并预读其后的几个页面(一般是三个页面),然后将数据放入页缓存中。
页缓存写策略:当进程发起 write 调用时,会先写到页缓存,然后方法返回。此时数据并没有真正保存到文件中,Linux 只是将页缓存中的这一页数据标记为 “脏”,并且被加入到脏页链表中。然后,由 flusher 回写线程周期性将脏页链表中的页写到磁盘,让磁盘中的数据和内存中保持一致,最后再清理“脏”标识。
一般导致脏页回写的情况有三种:即当空闲内存低于一个特定阈值时;或者脏页在内存中驻留超过特定时间;再就是进程发起了 sync() 或 fsync() 系统调用。
1.3. 直接IO
直接IO是相对缓存IO来说的,在Linux中打开文件,如果不指定flags为O_DIRECT,那么就是使用缓存I/O来对文件进行读写操作。
1 | /** |
O_DIRECT (Since Linux 2.4.10)
Try to minimize cache effects of the I/O to and from this file. In general this will degrade performance, but it is useful in special situations, such as when applications do their own caching. File I/O is done directly to/from user space buffers. The I/O is synchronous, that is, at the completion of a read(2) or write(2), data is guaranteed to have been transferred.
意思是,为了写文件或者读文件的 I/O 高度缓存开销的最小化。一般情况下,该标志会降低性能,但是,在特殊情况下,还是有作用的。例如当应用程序使用自己的高速缓存的时候,文件 I/O 直接接触到用户内存,I/O 操作是同步的,也就是说,一旦 read(2) 或者 write(2) 完成,数据可以保证传输完毕。
直接 I/O 省去了与内核缓存的复制过程,这样虽然使单次 I/O 访问效率高了,但由于没有了缓存,将导致访问 I/O 设备的操作更加频繁,而访问 I/O 设备的延迟要远高于内存间的复制的,因此需要应用自己去权衡。一般的在数据库服务中,会更倾向于建立自己的缓存机制,因为它们往往比操作系统更了解磁盘中存放的数据,从而可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
1.4. 内存映射IO
操作系统一般都会采用虚拟内存(参考笔记:计算机 存储系统),比如对于32位操作系统,应用进程可以拥有3G的空间,但是对于同时存在的进程,如何让每个进程都感觉自己拥有整个的内存空间,而且互相不影响呢?其实每个进程都有自己的内存映射表,维护着虚地址与内存物理地址的映射关系,进程在实际运行时,可能只需对少部分地址进行映射,即只占用实际物理内存的一部分,这样对于CPU而言,当发生进程切换时,只需要切换进程对应的地址映射表,就能访问到对应的进程空间了。
内存映射就是走的虚拟内存方式,而不再像上面一样先打开文件然后再进行读写了。其过程是先建立磁盘文件地址与进程虚拟内存的映射,然后访问文件就相当于访问内存,当然真正访问时还要通过 MMU 将逻辑地址转换成物理地址,如果 MMU 在地址映射表中无法找到对应的物理地址,将产生一个缺页中断,然后将尝试从 swap 中寻找对应的页面,如果还找不到则根据前面建立的映射关系从磁盘读取。但是之后的读写就完全是对内存的操作了,而对应的修改会触发脏页回写,从而保证数据更新到磁盘。
对应的,Linux提供了相关的系统调用:
1 | /** |
2. 网络I/O
对于网络 I/O,由于网络上数据分组到达的延时比较高,因此主要考虑的是如何降低网络延迟对应用进程的阻塞影响。
在具体讨论之前,需要先搞清楚同步和阻塞的概念:
同步与异步:描述的是用户线程的处理方式,同步指用户线程发起IO请求后需要等待或者轮询,直到内核 I/O 操作完成后才能继续执行;而异步是指用户线程发起 I/O 请求后仍然继续执行,当内核 I/O 操作完成后会通知用户线程,或者调用用户线程注册的回调函数。
阻塞与非阻塞:描述是内核 I/O 的处理方式,阻塞是内核等待 I/O 操作需要彻底完成后才返回;而非阻塞是指 I/O 操作被调用后立即返回给用户一个状态值,无需等到 I/O 操作彻底完成。
对于网络 I/O 操作,可以抽象成对 Socket 流的读写,分为两个阶段:
- 数据准备:等待网络上的数据分组到达,然后复制到内核缓冲区
- 数据拷贝:将数据从内核缓冲区复制到应用进程空间

2.1. 阻塞IO
这种处理比较简单,即用户进程走recv系统调用,然后交给内核处理并进行等待,内核完成操作后再返回给进程,但进程在等待期间将一直处于阻塞状态,而这里的等待包括了上面两个阶段。
其优点是可以及时返回数据,无延迟,而且实现简单,而缺点则是进程一直处于阻塞等待,程序性能较低。
2.2. 非阻塞IO
即内核在进程发出调用后会立即响应一个状态,但这个状态可能是数据还没准备好,因此需要进程自己处理轮询检测状态。
其优点是进程可以在等待期间去做一些其它事情,而缺点是数据接收可能有延迟。
2.3. 多路复用IO
这种方式相当于内核为进程提供了一个状态的轮询服务,进程将对应的socket流注册到轮询服务,这样由操作系统统一负责对多个sockect进行轮询。站在进程的角度,这种方式依然是阻塞的,区别在于之前是直接阻塞在socket上,而现在是阻塞在轮询服务上。这样的方式可以节约计算机资源,因为进程可以用一个线程来同时服务多个socket请求了。
具体的,Linux提供了三种轮询服务:
select:select系统调用允许程序同时在多个底层文件描述符上,等待输入的到达或输出完成。它以数组的形式组织文件描述符(64位机器默认2048个),当有数据准备好时,无法感知具体是哪个流OK了,所以需要一个一个的遍历,函数的时间复杂度为O(n)。
poll:本质与select相同,只是以链表形式存储文件描述符,没有长度限制,时间复杂度也是O(n)。
epoll:基于事件驱动,如果某个流准备好了,会以事件通知,知道具体是哪个流,因此不需要遍历,时间复杂度为O(1)。
2.4. 信号驱动式IO
这种方式是先注册一个信号处理函数,然后进程继续运行,当数据准备好的时候,内核向应用程序发送一个信号,进程对信号进行捕捉,并且调用信号处理函数来获取数据报。
其在数据准备阶段是不阻塞的,当数据准备完成之后,会主动通知进程数据已经准备完成,对用户进程做一个回调,但数据拷贝阶段仍是阻塞的,等待数据拷贝。
2.5. 异步IO
进程进行 aio_read 系统调用之后,无论内核数据是否准备好,都直接返回,然后进程去做别的事情。等到 socket 数据准备好了,内核直接复制数据给进程空间,然后再向进程发送通知。
其在整个阶段都是非阻塞的,直接由内核完成后通知进程。
3. Linux零拷贝 sendfile
sendfile 系统调用在内核 2.1 引入,它可以直接在文件描述符与Socket描述符之间传递数据,即直接在内核中操作,从而避免了在内核区与用户区之间的拷贝,因此被称为零拷贝。
1 | sendfile(socket, file, len); |
其流程大概如下:
sendfile系统调用,文件数据被copy至内核缓冲区
然后从内核缓冲区copy到内核中socket相关的缓冲区
最后再从socket缓冲区copy到协议引擎
内核在 2.4 之后,文件描述符结构被改变,引入了 gather机制, sendfile 实现了更简单的方式,当文件数据被拷贝到内核缓冲区时,不再将数据 copy 到 socket 缓冲区,而是只将记录数据位置和长度相关的数据保存到 socket 缓存,而实际的数据则由 DMA 模块直接发送到协议引擎,再次省去了一次 copy 操作。
参考: