Kafka Consumer
words: 2.1k views: time: 7minKafka Consumer是Kafka事件(消息)的消费端客户端,它是Kafka的关键组件之一。为了确保Kafka集群的高效运行,Kafka的客户端被设计为富客户端,例如,消费者组中的分区分配就是在客户端完成的。
消费者的角色
Kafka consumer一般是以group的形式消费的,group中的每个成员称为一个consumer member
根据分配到的角色,可以进一步划分为:
- leader:特殊的一个member,负责分配所有member到topic partition的映射;
- follower:除了leader以外的其他所有 member;
消费流程涉及的核心组件
Kafka consumer会不断与kafka broker通信
broker侧组件:
- group coordinator:负责同步consumer member状态、监听心跳、触发 rebalance、挑选consumer leader等行为;
- replica manager: 负责topic partition副本的管理(读、写等);
consumer侧组件:
- metadata:Kafka集群的元信息;
- client:ConsumerNetworkClient实例,负责网络层读写;
- assignors:consumer leader中负责指定所有consumer member到topic partition的映射;
- coordinator:ConsumerCoordinator实例,负责与broker侧的group coordinator交互;
- fetcher:负责拉取消息;
常用接口
Kafka的consumer常用接口:
- subscribe:指定consumer订阅的topic
- poll:拉取消息
- close:优雅退出 consumer
- commit: 手动提交消费位点
在Kafka中,subscribe主要用于更新消费者状态信息,而commit则是将特定位点发送给broker。这两个接口的逻辑相对简单,我们不会在本文中详细展开讨论。接下来的章节将重点介绍poll和close两个接口的交互和原理。
consumer与broker交互流程解析
下图展示了 consumer 和 broker 在消费过程中的交互逻辑,总体可以分为“消费过程”和“退出过程”
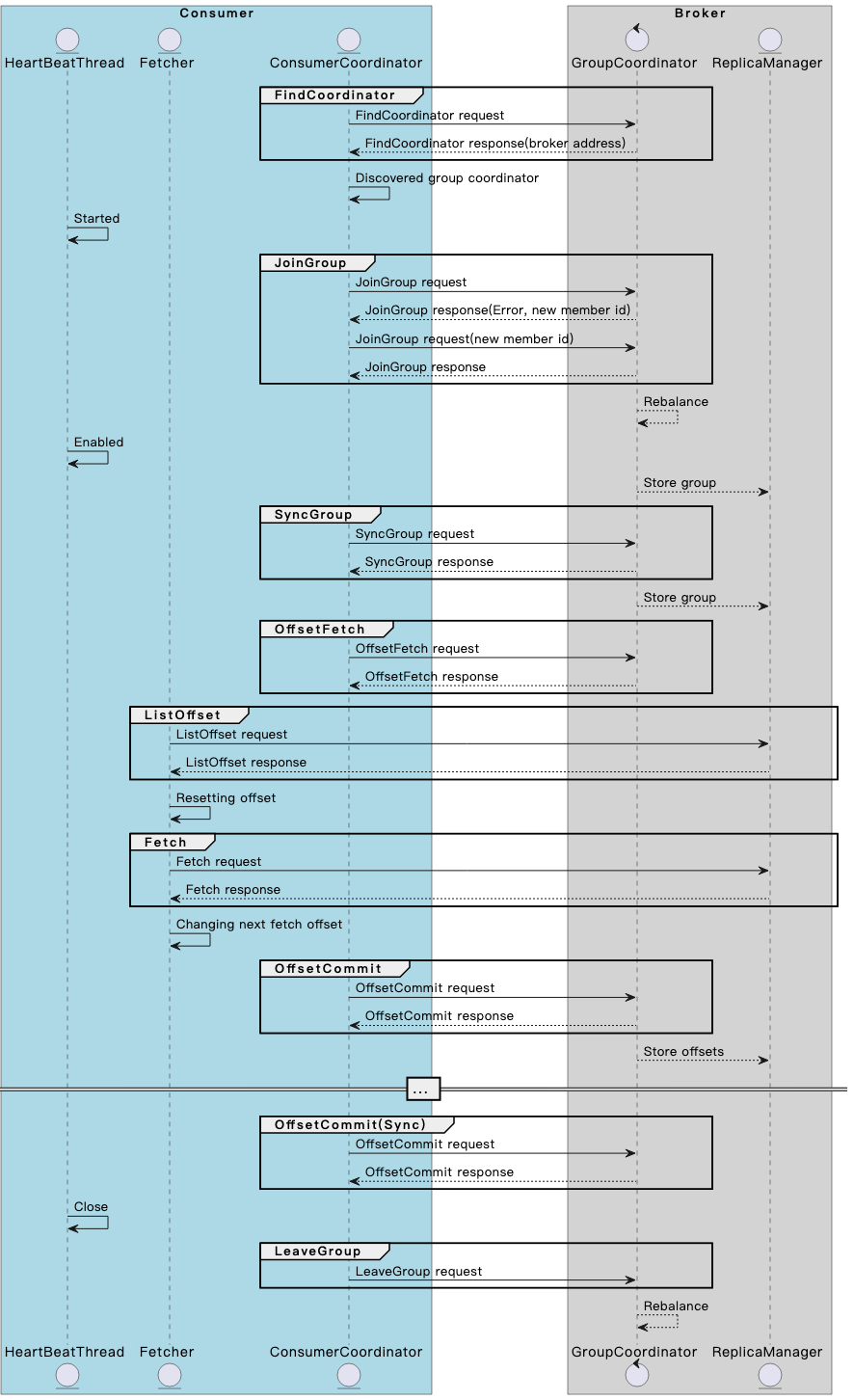
消费过程
消费过程大体可以分为两块逻辑:
- 加入consumer group,获取负责的topic partition;
- 基于负责的topic partition,向所在的broker拉取消息;
加入consumer group
FindCoordinator阶段
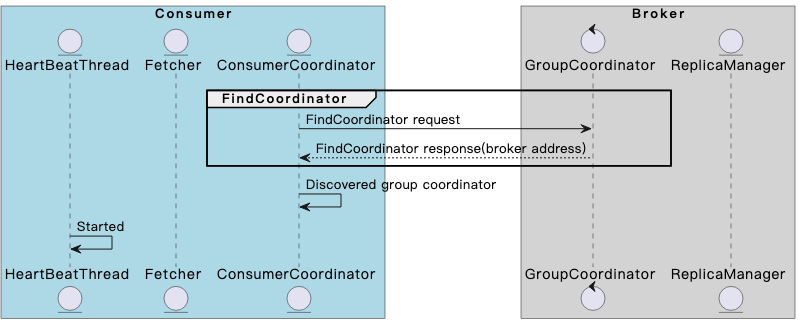
每次调用KafkaConsumer#poll时,都会触发ConsumerCoordinator#poll的调用,确保consumer到GroupCoordinator的通信是正常的。
在consumer第一次poll时,肯定是找不到GroupCoordinator的,于是:
Consumer向最近通信过的broker发送FindCoordinator请求;
该broker根据group.id进行hash,再对__consumer_offsets的partition数目取模,找到负责该group的 partition后,返回partition leader所在的broker地址;
Consumer从FindCoordinator response中解析出负责本group的broker的地址,后续Consumer侧的coordinator组件会与新broker通信,同步consumer group的状态;
在本阶段执行到最后时,HeartBeatThread线程将会启动,该线程主要负责向broker侧的GroupCoordinator发送心跳。GroupCoordinator会在HeartBeat response附带一些信息,例如指向了错误的GroupCoordinator、consumer group正在重平衡等信息。
但此时consumer还没有加入group,HeartBeatThread虽然启动了,但没有enable,还不会向GroupCoordinator发送心跳
JoinGroup阶段
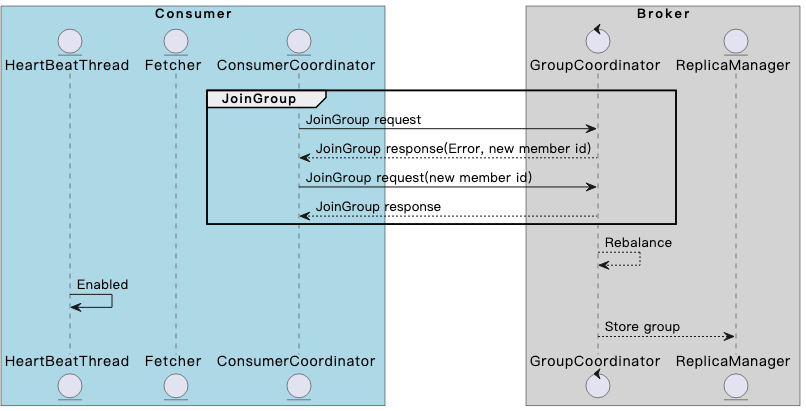
如果consumer还没有加入consumer group,那么会向GroupCoordinator请求加入group:
Consumer发送JoinGroup请求;
GroupCoordinator会检查JoinGroup请求的合法性。consumer在构造的时候是没有member id的,GroupCoordinator会为这个新consumer生成一个member id,随MEMBER_ID_REQUIRED异常一并返回;
Consumer填入member id,再次发送JoinGroup请求;
GroupCoordinator会在JoinGroup response中告知consumer,当前group leader的member id以及consumer自己的member id。对于leader,会额外返回所有consumer的member id,以便leader进行后续的partition分配工作。
在该阶段最后,GroupCoordinator会将该consumer group置为rebalance状态,从而触发group内其他member进行rejoin group动作。此时,HeartBeatThread也会被enable,开始与GroupCoordinator的心跳通信。
开始rebalance后,broker会等待consumer加入group。等待会有超时时间,超时后broker会踢出没有及时加入group的旧member,将当前的group元数据持久化。
一般来说,group的consumer leader是第一个向GroupCoordinator发起JoinGroup请求的consumer。
member id是不可以手动设置的。但Consumer侧有个类似的配置是group.instance.id,用于声明consumer为静态consumer。静态consumer与普通consumer的最大区别在于退出时不会发送LeaveGroup请求。在用户业务升级时,普通 consumer退出后再拉起会导致较频繁的rebalance,静态consumer就可以规避这种情况(通常会搭配较大的 session timeout 配置)
SyncGroup阶段
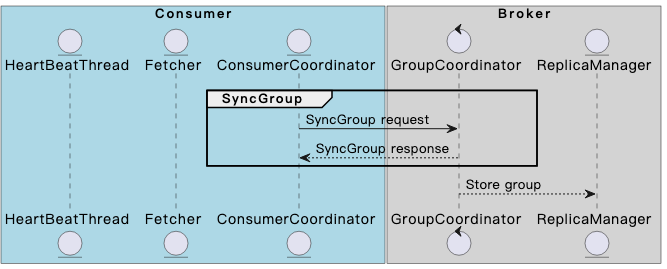
- 在consumer member中分配partition:
在收到JoinGroup response后,consumer group leader会根据指定的partition assignment strategy(partition.assignment.strategy设置),进行topic partition在各个member中的分配。
- consumer执行SyncGroup请求:
leader consumer会发送leader SyncGroup请求,附上topic partition与member的映射结果;其他member会发送follower SyncGroup请求,尝试获取自己需要负责的topic partition。
在该阶段最后,GroupCoordinator会持久化group的metadata到该group绑定的某个__consumer_offsets的partition中。
拉取消息
OffsetFetch阶段
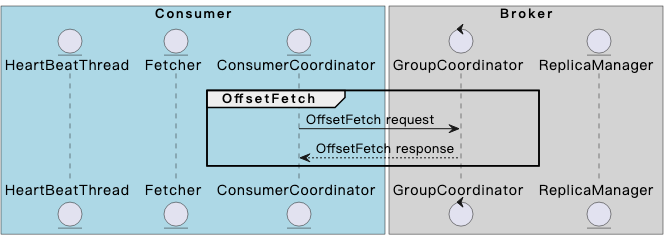
各个consumer member收到SyncGroup response以后,需要确定partition消费的起始位点。consumer会向GroupCoordinator查询该group关于指定partition已经提交的commited offset,
此时:
- 如果该partition查询到了commited offset记录,那么consumer会从该offset开始继续消费;
- 否则,根据consumer配置的auto.offset.reset,决定起始消费位点;
ListOffset阶段
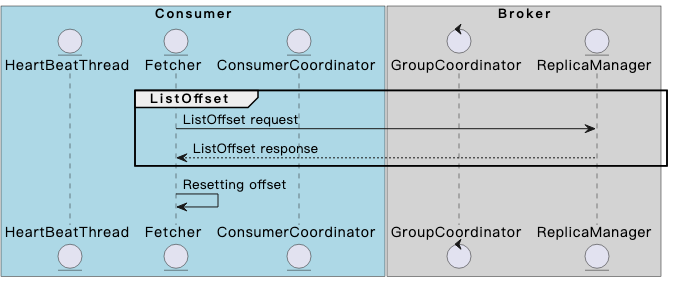
如果上一步中,partition没有查询到commited offset记录,那么consumer会利用ListOffset请求(基于auto.offset.reset对应的策略指定请求中的timestamp字段)的response,确定起始消费位点。
Fetch阶段
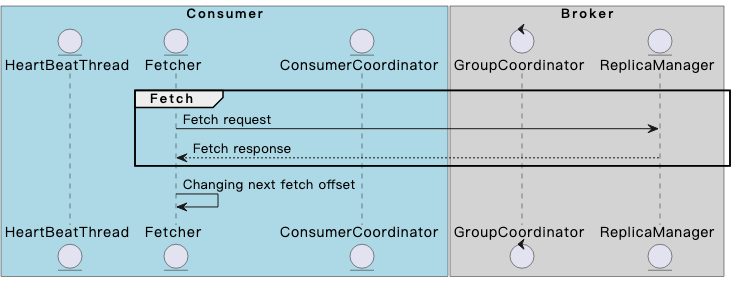
基于此前的offset信息,consumer向partition所在的broker发起拉取消息的请求,拉取成功后会更新下次需要拉取的位点。
OffsetCommit阶段
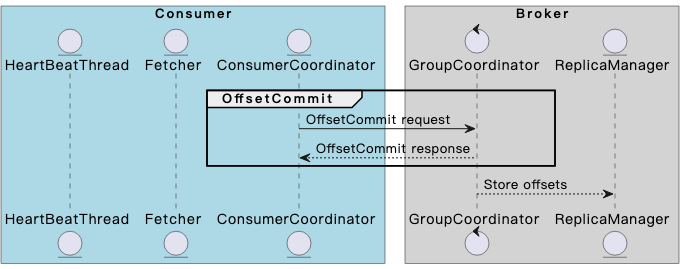
在消费过程中,consumer自动或手动地提交当前消费位点到GroupCoordinator处。类似于SyncGroup请求,GroupCoordinator会将该位点信息持久化。
退出过程
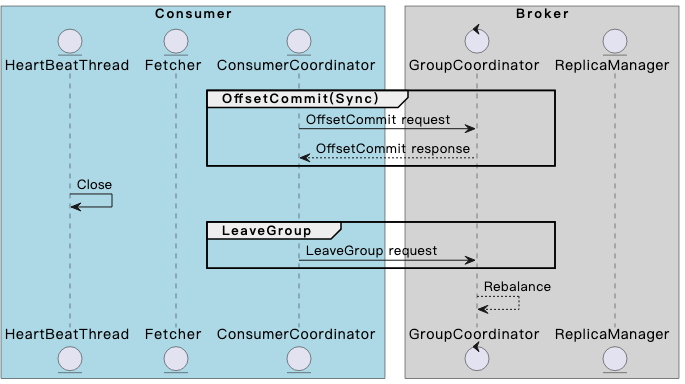
Consumer同步提交位点信息;
关闭Heartbeat线程;
Consumer发送LeaveGroup请求到GroupCoordinator,但不会阻塞式等待response;
GroupCoordinator收到LeaveGroup请求后,将group置为rebalance状态,触发该group中其他member的重平衡。
Consumer关闭时不会阻塞等待LeaveGroup的response,这样设计是为了加速consumer的关闭,另外即使broker没有收到Consumer发送的LeaveGroup请求,也会由于心跳超时被踢出consumer group。
broker侧consumer group状态管理
broker侧group metadata存在一个字段,标志当前group的状态:
- Empty:group没有member,等待offsets信息失效。常作为初始状态;
- PreparingRebalance:rebalance开始,前文中提到的broker会通知所有member重平衡,就是在这个状态下通知的;
- CompletingRebalance:等待group leader提交分配结果;
- Stable:group稳态(所有consumer都在正常消费);
- Dead:group没有member,且offsets信息为空;Dead是最终状态,不可转化为其他状态;
状态机视图如下:
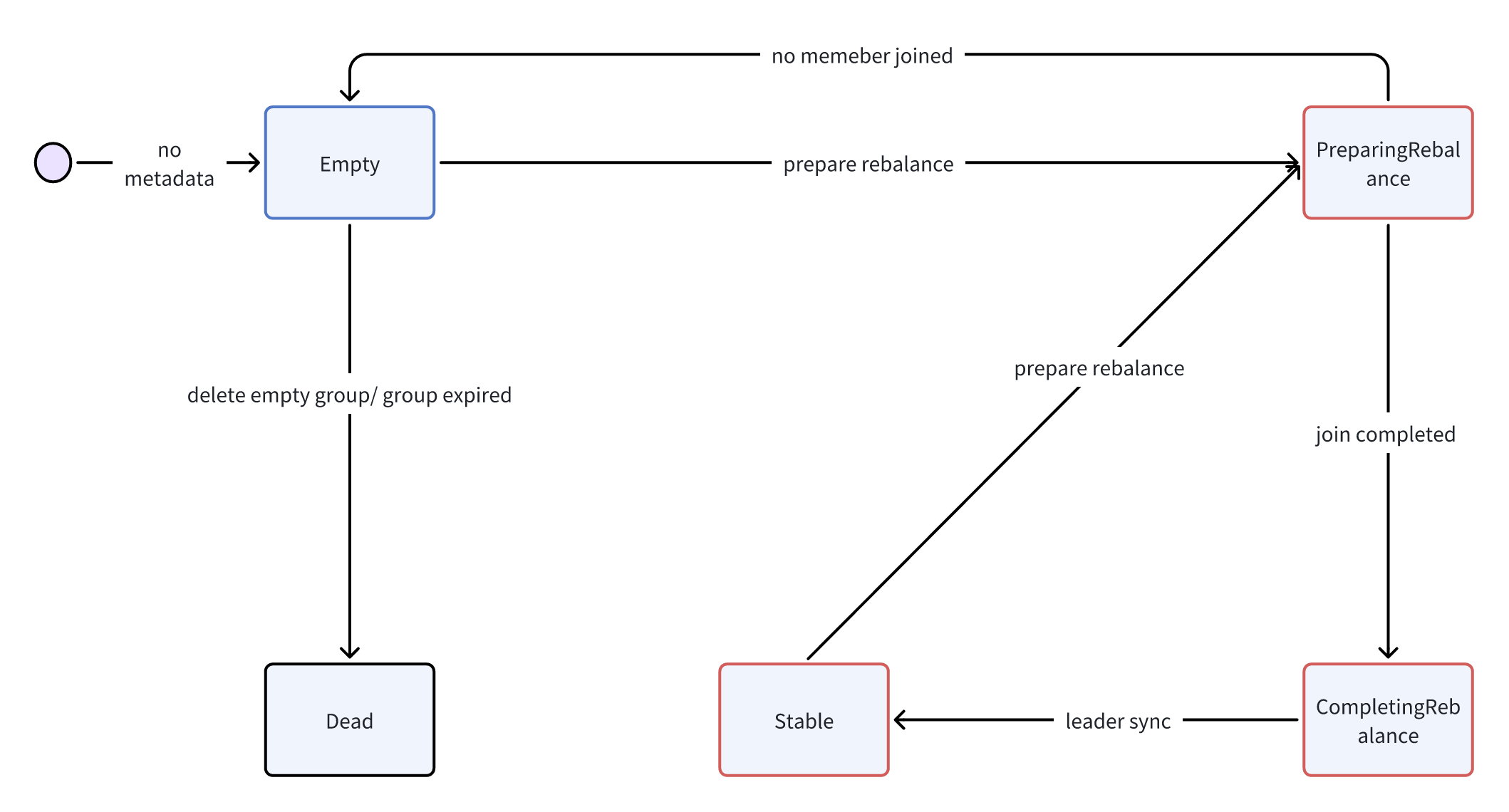
上图中为了简略性,只列出了两个常见的转化为 Dead 状态的情况,实际上以下四种情况都会导致状态转为 Dead:
- Empty Group(没有member)的手动删除;
- Group metadata失效(offsets信息为空),原因一般是定时任务清理掉了所有offsets(已失效);
- OffsetsDelete或PartitionsDelete之后,如果offsets被清空且Group是Empty;
- GroupUnload,即__consumer_offsets的某个partition的leader从本机切出去,将内存中cache的相关Group metadata置为Dead;
rebalance实现
rebalance是Kafka中consumer group中的一个关键操作,用于在consumer group中实现负载均衡和容错。
rebalance的触发时机:
- Group刚创建(第一个consumer发起JoinGroup请求);
- consumer到GroupCoordinator的心跳超时,被移除出group;
- 新的consumer加入group;
- Consumer Group订阅的某个topic的partition数目增加了;
- Consumer Group使用通配符订阅规则,并且有新的匹配的topic被创建了;
rebalance状态的通知:
附在HeartbeatResponse或者OffsetCommitResponse中,以error code形式告知consumer需要rejoin group。
重平衡Q&A
PreparingRebalance状态下是否会停止消费?
当且仅当consumer感知到自己需要rejoin group才会停止消费。PreparingRebalance状态下可以正常消费和提交位点。不过CompletingRebalance状态下不允许提交位点,会抛出Errors.REBALANCE_IN_PROGRESS,触发consumer 的rejoin动作。
Consumer手动assign和rebalance两种模式的区别?
1 | consumer.assign(Collections.singleton(new TopicPartition("test-topic", 0))); |
手动assign时Kafka consumer跟topic partition是静态绑定的,Kafka consumer不会参与重平衡;rebalance模式会根据consumer加入、退出等情况触发重平衡,调整各个Kafka consumer分配到的topic partition;
两种模式互斥,assign模式下,Kafka consumer不支持动态扩容,当生产速率突增时,无法及时加入新的消费者来提升消费的速率。如果业务希望完全避免消费过程中出现topic partition 漂移(一种可能的场景是,生产者将 user_id 作为 record key,且消费时要求只能有一个consumer处理同一个user的数据),那么才有必要考虑使用assign模式。