Kafka Producer(上)
words: 2.6k views: time: 10min关于Kafka Producer的使用方法与实现原理
使用示例
1 | Properties kafkaProps = new Properties(); |
- Kafka Producer的主要接口
1 | public class ProducerRecord<K, V> { |
ProducerRecord
Producer发送出的一条消息,包含以下属性:
- topic:必选。用于指定该record发送到的topic
- partition:可选。用于指定该record发送到的partition序列(zero-indexed),未设置时使用用户指定的Partitioner或内置的BuiltInPartitioner选择分区
- headers:可选。用户自定义的额外键值对信息
- key:可选。消息的键值
- value:可选。消息的内容
- timestamp:可选。发送消息的时间戳。如果用户未指定timestamp,则使用创建这条消息的时间。如果topic的message.timestamp.type配置为”CreateTime”或”LogAppendTime”,则无论用户是否指定了timestamp,都使用消息在broker上写入时的时间
Callback
用于发送消息ack后的回调。可能发生的Exception有:
不可重试
- 超过了producer单个请求的最大大小(producer配置max.request.size,默认 1MiB)
- 超过了producer buffer的大小(producer配置buffer.memory,默认 32MiB)
- 超过了允许的最大大小(broker配置message.max.bytes或topic配置max.message.bytes,默认 1MiB + 12 B)
- 超过了segment的大小(broker配置log.segment.bytes或topic配置segment.bytes,默认 1 GiB)
- InvalidTopicException:topic的名称不合法,例如过长、为空、使用非法字符等
- OffsetMetadataTooLarge:调用Producer#sendOffsetsToTransaction时,使用的Metadata字符串过长(由offset.metadata.max.bytes控制,默认 4 KiB)
- RecordBatchTooLargeException:发送的batch的大小
- RecordTooLargeException:单条消息的大小
- TopicAuthorizationException、ClusterAuthorizationException:鉴权失败
- UnknownProducerIdException:事务请求中,PID已过期或PID关联的record均已过期
- InvalidProducerEpochException:事务请求中,epoch非法
- UnknownServerException:未知错误
可重试
- 同步调用耗时过长,例如producer buffer满、拉取metadata超时等
- 异步调用超时,例如producer被限流导致没有发送、broker超时未响应等
- UnknownTopicOrPartitionException:topic或partition不存在,可能由metadata过期导致
- NotLeaderOrFollowerException:请求的broker不是leader,可能正在选举leader
- FencedLeaderEpochException:请求中的leader epoch过期,可能由metadata刷新慢导致
- CorruptRecordException:CRC校验失败,通常由网络错误导致
- InvalidMetadataException:Client侧的metadata过期
- NotEnoughReplicasException、NotEnoughReplicasAfterAppendException:insync replica数量不足(broker配置min.insync.replicas或同名topic配置,默认1)。注意NotEnoughReplicasAfterAppendException会在record写入完成后发现,重试会导致数据重复
- TimeoutException:同步调用耗时过长,例如producer buffer满、拉取metadata超时等,或者异步调用超时,例如producer被限流导致没有发送、broker超时未响应等
Producer#send
异步地发送一条消息,如果需要,可以在本条消息ack后触发Callback。Producer能保证同一个partition的send请求的Callback会按调用顺序依次触发
Producer#flush
标记producer缓存中的所有消息立即可用于发送,并阻塞当前线程,直至在此之前的所有消息都被ack。
只是阻塞当前线程,其他线程仍可以正常发送,然后对调用flush方法后发送的其他消息的完成时机则没有保证。
Producer#close
关闭producer,并阻塞等待至所有消息发送完成。
- 在Callback中调用close会立刻关闭producer
- 对仍处于同步调用阶段(拉取 metadata、等待分配内存)的send方法将会立即终止,并抛出KafkaException
核心组件
- ProducerMetadata & Metadata
负责Producer侧所需元数据的缓存与刷新,其中包含Kafka Cluster的所有元数据,例如broker地址、topic中的partition分布状态、leader与follower信息。
- RecordAccumulator
负责维护Producer的缓冲区。它会将待发送的消息按照partition的维度、基于时间(linger.ms)和空间(batch.size)攒为RecordBatch,并等待发送。
- Sender
维护一个守护线程 “kafka-producer-network-thread | {client.id}”,负责驱动发送Produce请求和处理响应,同时负责超时处理、错误处理与重试。
- TransactionManager
负责实现幂等(idempotence)与事务(transaction)。包括分配序号(sequence number)、处理消息丢失与乱序、维护事务状态等。
发送流程
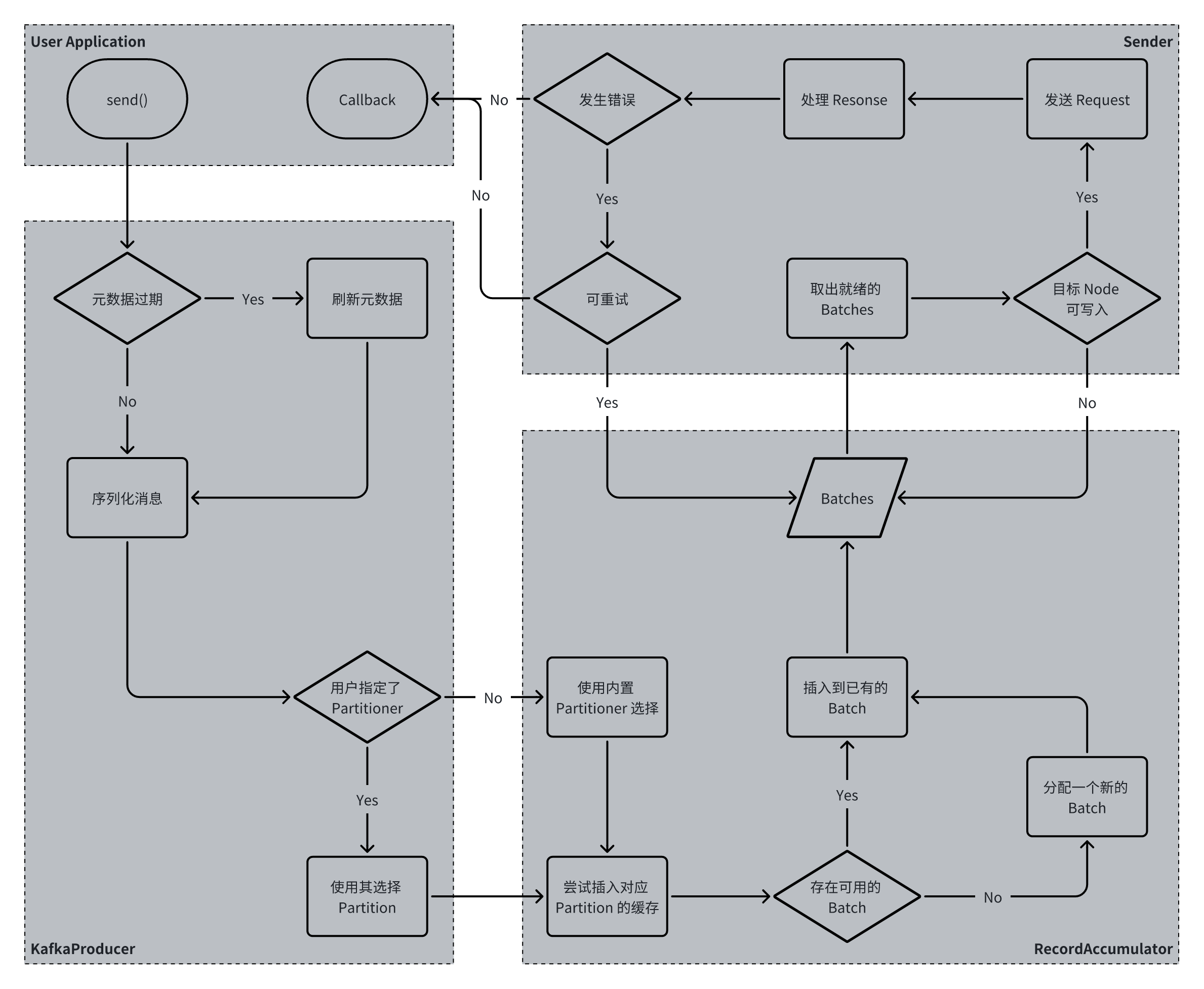
步骤:
- 刷新元数据;
- 使用指定的Serializer序列化消息;
- 使用用户指定Partitioner或BuiltInPartitioner选择发送消息的目标partition;
- 将消息插入到RecordAccumulator进行攒批;
- Sender异步地从RecordAccumulator中取出可发送的batch(按照 node 分组),注册回调,并发送;
- Sender处理响应,并根据情况返回结果、返回异常或重试。
刷新元数据
ProducerMetadata会维护一个topic视图,其中包含producer所需的所有topic。常见以下场景:
增加topic
当发送消息时,指定的topic不在缓存的元数据中
移除topic
当发现某个topic的元数据已经持续metadata.max.idle.ms未被使用时
刷新元数据
- 当发送消息时,指定的partition不在缓存的元数据中(这会发生在topic的partition数量增加时);
- 当发送消息时,指定partition的leader未知
- 当发送消息后,收到了InvalidMetadataException响应
- 当持续metadata.max.age.ms未刷新元数据时,默认5min,或持续metadata.max.idle.ms未向topic发送消息时,默认5min
分区选择
KIP-794[3]中,为了解决旧版本中Sticky Partitioner导致的“向更慢的broker发送了更多的消息”的问题,提出了一个新的Uniform Sticky Partitioner(并作为默认的内置 Partitioner)。在没有key的限制时,它会向更快的broker发送更多的消息。
在进行分区选择时,分为以下两种情况:
如果用户指定了Partitioner,则使用该Partitioner选择partition
如果没有,则使用默认内置的BuiltInPartitioner
拥有相同key的record会始终被分配到同一个partition;
但当topic的partition数量变化时,不保证变化前后相同的key仍会分配到同一个partition;
如果设置了record key,则基于key的哈希值唯一选择一个partition;
如果没有设置key,或者partitioner.ignore.keys设置为 “true”,则使用默认策略——向更快的broker发送更多的消息;
相关配置
- partitioner.class
分区选择器的类名,可以由用户根据需求自行实现,提供了一些默认实现
- partitioner.adaptive.partitioning.enable
是否根据broker的速度决定发送消息的数量,若不开启,则会随机地选择partition。仅在未配置partitioner.class时生效,默认为”true”
- partitioner.availability.timeout.ms
仅在partitioner.adaptive.partitioning.enable设置为”true”时生效。当”为指定broker攒出一批消息的时间点”和”向指定broker发送消息的时间点”相差超过此配置时,则不再向指定broker分配消息;仅在未配置partitioner.class时生效,默认为0。
- partitioner.ignore.keys
选择partition时是否忽略消息的key,若为false,则根据key的哈希选择partition,否则忽略key值。仅在未配置partitioner.class时生效,默认为false
消息积攒
RecordAccumulator中,按照partition维度维护了所有待发送的batch,主要有几个方法:
1 | public RecordAppendResult append(String topic, |
- append
将消息插入到缓冲区,注册一个future并返回,该future会在消息发送完成(成功或失败)时完成。
- ready
筛选出所有拥有可发送消息的node列表。有以下几种情况:
已经攒批出batch.size大小的消息
已经持续攒批超过了linger.ms时间
分配给producer的内存已耗尽,缓冲区的消息大小总和超过了buffer.memory
需要重试的batch已经等待至少retry.backoff.ms时间
用户调用了Producer#flush以强制发送消息
正在关闭producer
- drain
对于每个node,遍历其上的每个partition,取出每个partition上最早的batch(如果有),直至攒够max.request.size大小的消息,或遍历完所有partition
相关配置
- linger.ms
每个batch会等待的最大时间,默认为0。设置为0时,不意味着不再进行攒批,而是不在发送前进行任何等待。如果希望禁止攒批,应将batch.size设置为0或1
- batch.size
每个batch的最大大小。默认为16KiB。当设置为0(等价于设置为1)时,则会禁用攒批
- max.in.flight.requests.per.connection
在未收到响应前,producer向每个broker发送batch的最大数量,默认为5
- max.request.size
每次请求中消息总大小的最大值,同时也是每条消息的最大大小。默认为1MiB。另外broker配置message.max.bytes 和 topic配置max.message.bytes也对每条消息的最大大小做出了限制
超时处理
Kafka Producer定义了一系列超时相关的配置,用于控制发送消息的各个阶段允许耗时的最大值
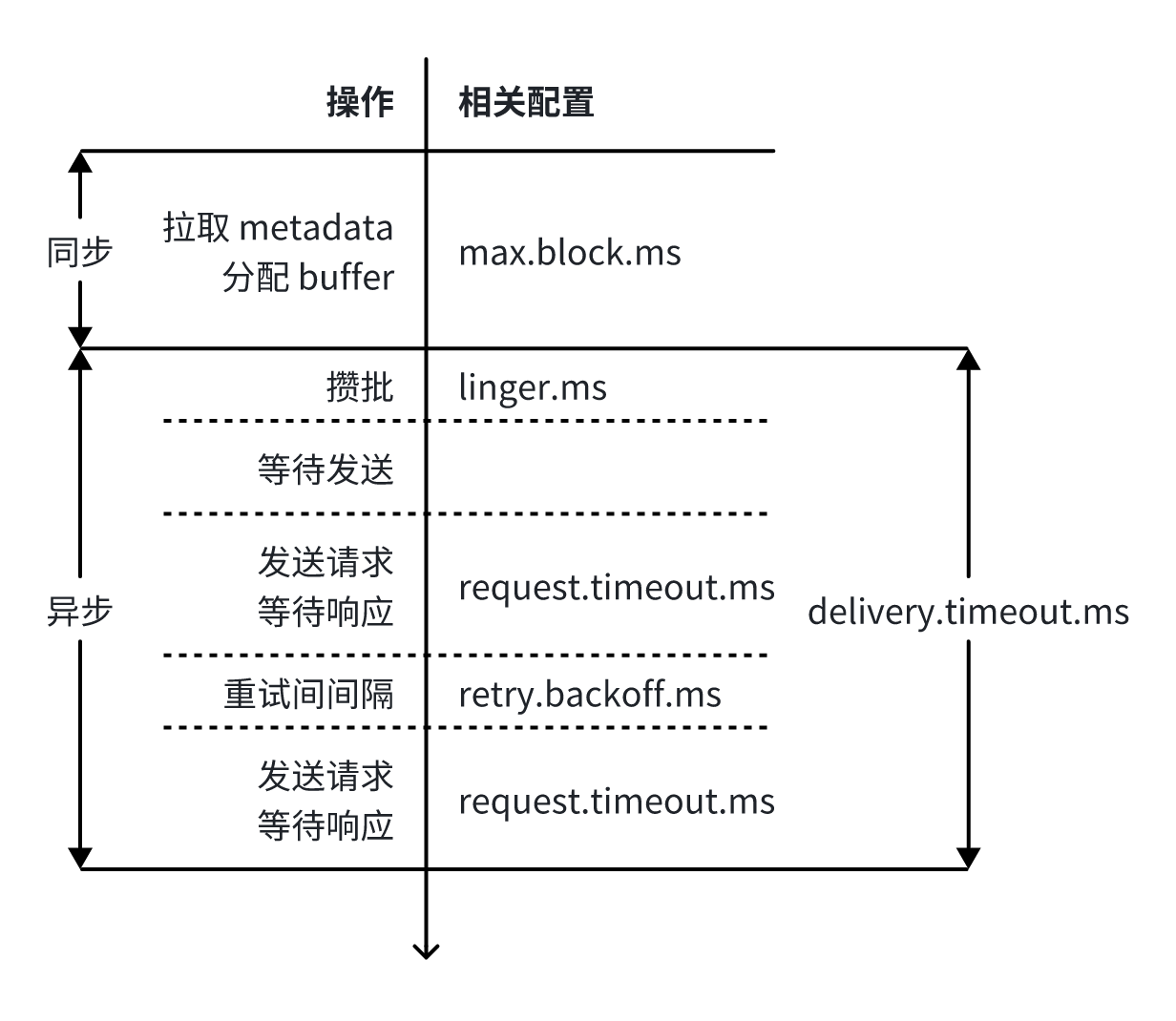
相关配置
- buffer.memory
producer buffer的最大大小,默认为32MiB。当buffer耗尽时,会阻塞地等待最多max.block.ms时间,随后报错
- max.block.ms
调用send方法时,会阻塞当前线程的最长时间,默认60s。包含拉取metadata的时间和producer buffer的阻塞等待时间
- request.timeout.ms
从发送请求到收到响应的最长时间,默认30s
- delivery.timeout.ms
异步发送消息的最长总耗时,从send方法返回后,到触发Callback的总耗时,默认120s。它的值应不小于linger.ms + request.timeout.ms
- retries
重试的最大次数,默认为Integer.MAX_VALUE。
- retry.backoff.ms与retry.backoff.max.ms
二者组合控制发送失败后重试的指数退避策略——随着重试次数的增加,从retry.backoff.ms开始按照2的指数次幂增加重试等待时间,并增加一个20%的扰动,且最大不超过retry.backoff.max.ms,默认为 100ms/1000ms。